|
2.1 設計方針
Pyxisの目的は,"M集合のCGを高速に作成する" ためのハードウエアです.これを第1目標として設計するわけですが,当時の状況などの制約事項を考慮し,次のように設計目標を定めました.
(a)400×320ピクセル分を1分以内で描画できること.
(b)IC代で2〜3万円が上限.
(c)特殊な部品は使わない.
(d)拡大描画に耐える十分な演算精度を持つ.
(e)ホストの性能を期待しない.
全般に最適なトレードオフを得るためには,システム全体の様々な問題に対し上記の条件のもとで,あたかも
"ニュートン法を使って連立方程式を解く" ような設計をする必要があります.その
"連立方程式" の最適解を目標としてPyxisを設計しました.
|
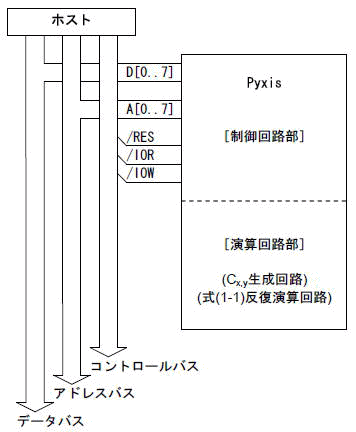
[図2-1]ホストとの接続形態
|
2.2 システム的機能
図2-1にPyxisのホストとの接続形態を示します.
Pyxisは8ビットCPUバスに直結され,単純なI/Oとして動作します.
まず,ホストからは第1章で説明した4つのパラメータをPyxisの内部レジスタに設定します.
(a)描画対象領域実軸原点:a1(図1-1参照)
(b)描画対象領域虚軸原点:b1(図1-1参照)
(c)ステップ:S(式(1-3)参照)
(d)最大反復回数:NMAX
そしてリセットレジスタをクリアすると,Pyxisは演算を開始します.
この後ホスト側に必要な処理は,Pyxisから順次出力される全ピクセル分の演算結果Nx,yを読み出し,描画していくだけです.ホストの能力に依存せず高速な描画を実現するため,各ピクセルに対応するCx,Cyの計算など,演算にからむ処理はPyxis内部ですべて処理されます.ですから,機能的にはリスト1-1の描画部分(draw_pixel())を除いた,すべての処理を取り込んだものとなっています.
2.3 動作の概要
前項の通り,Pyxisは機能的にリスト1-1をハードウエア化したものとなっています.ここではその動作について概略を説明します.
(1)処理の進み方
処理はP0,0を開始点として,まずx方向に0からXMAX-1まで,さらにこれをy方向にYMAX-1まで順次進行していきます.この時ピクセル毎のCx,yは,Cx生成回路及びCy生成回路にて処理の進行にあわせて計算されます.
Pyxisはパイプラインにより2ピクセル分を同時に処理します(後述).x方向への処理進行において,まずP0,0とP1,0,次にP2,0とP3,0,・・・と2ピクセルずつ順次処理されていきます.この同時に処理される2ピクセルのことを以後ピクセルペアと呼び,xが偶数,奇数のピクセルをそれぞれPE,PDで表すことにします.
(2)ピクセルペア毎の処理
演算処理はピクセルペア毎に行われます.n=0から,式(1-1)の反復演算を実行していきます.
その処理の中で,PE,PDのそれぞれについて式(1-5)の成立がチェックされます.成立と判定された場合にはそのフラグが制御回路へ渡され,その時のnが結果レジスタLEもしくはLDへロードされます.当然,PEとPDが同時に成立するとは限りません.先に成立した方は,他方の処理が終了するまで待たされます.
このようにして,PE,PDの両方が式(1-5)成立と判定されるか,またはnがNMAX-1に到達するとそのピクセルペアの処理は終了となります.演算終了ステータスがセットされ,ホストに対して結果レジスタLE,LDの読み出しが可能になったことを知らせます.演算終了ステータスは,LDレジスタの読み出しでクリアされます.
(3)1ピクセルペアの処理終了後
演算終了ステータスがセットされた後,Pyxisは直ちに次のピクセルペアの処理を開始します.ホストの読み出しを待ちませんので,回路の動作効率を非常に高めることができます.
しかし万一,ホストの処理が遅くて読み出しが間に合わない場合(すなわち,演算終了ステータスがセットされた状態で,処理中である次のピクセルペアPE,PDのどちらかの演算が終了した場合)には,結果レジスタがオーバーライトされる直前の状態で回路全体が停止し,ホストの読み出しの完了を待つようになっています.これにより,ホストが遅くても演算結果を読み落とす心配はありません.
○ここまでで,Pyxis全体の構成及び動作の概略を説明しました.次の章では,具体的な回路の説明の前に必要となる,数値データの表現法などシステム全体に共通する基本的な重要要素について説明します.
|