|
4.1 システムブロック
Pyxisの全回路は4つの階層に分けられた機能ブロックの集合体として構成されています.この階層構造については後述しますが,まず第1階層は次の6つの機能ブロックで構成されています.
(a)Cx生成回路 ・・・・・・・・・・・・・・・・・・・Ox
(b)Cy生成回路 ・・・・・・・・・・・・・・・・・・・Oy
(c)Zx2−Zy2+Cx演算回路 ・・・・・・・Xx
(d)2ZxZy+Cy演算回路 ・・・・・・・・・Yy
(e)Zx2+Zy2演算回路 ・・・・・・・・・・・・Rr
(f)制御回路 ・・・・・・・・・・・・・・・・・・・・・・Cn
以後これらの部分を適宜右の2文字の略語で表します.
Ox,Oyは各ピクセルに対応するCx,Cyを生成します.Xx,Yy,Rrは各ピクセルについて式(1-1)の反復演算を行う部分です.それぞれ,式(3-1a),式(3-1b),式(3-1c)を演算します.Cnはホストインターフェースを含む全体制御回路です.
図4-1にPyxisのブロックダイヤグラムを示します.この図には,第2階層までが表現されています.制御回路部を除けば,図3-1の演算フローに忠実な構成になっています.
以降で,このシステムブロックを構成している各機能ブロックを説明していきますが,個別の説明に入る前に,まず演算回路部(a)〜(e)に共通の基本要素である"加算・減算回路"と"乗算回路"について説明します.
|
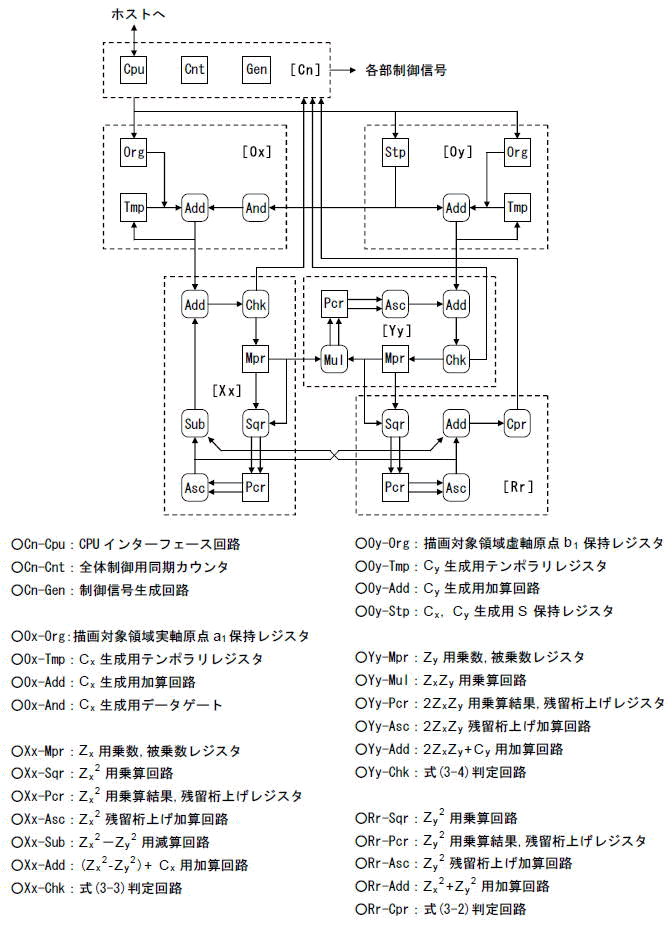
[図4-1]全体ブロック図
|
4.2 加算・減算回路
(1)状況の有効利用
パイプライン化により,加減算部でも乗算部と同じ演算時間を使うことができます.視点を変えて,これを有効に使えば,ハードウエアの規模を小さく押さえることができます.乗算より加減算の方が所要時間は短く,処理も少ないですから,許される時間内に演算が終わる程度のハードウエアを用意すれば十分です.
(2)アルゴリズム:加算回路
図4-2にPyxisの加算回路を示します.64ビットデータを8ビット毎8回に分けて,LSB側よりこの回路に通します.毎回の桁上げは,桁上げ保存レジスタCSRに保存され,次回にキャリー入力として加算されるようにします.これにより,64ビット分の加算器を8ビット分のハードウエアで実現できます.もちろんこの回路のためには,64ビットデータを8ビット毎にマルチプレクスして出力し結果をロードする回路がこのほかに必要となります.がPyxisではパイプライン化のためのステージ間レジスタがいずれにしても必要ですので,それにこの機能をあわせ持たせてあります.
|
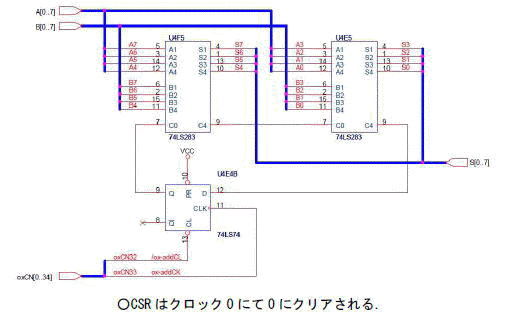
[図4-2]加算回路
|
(3)減算回路
また,この回路構成は簡単に減算回路にも対応できます.第2オペランド側の入力をビット反転し,CSRの初期値を1にします.これで2の補数となりますので,後は加算器と同様です(図4-3).
このように,加減算回路においては許容された時間を有効に利用することと,桁上げ保存を応用することで,ハードウエアの規模を大幅に縮小しています.
|
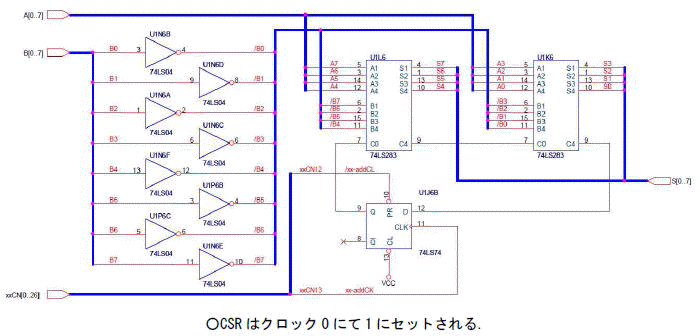
[図4-3]減算回路
|
4.3 乗算回路
(1)アルゴリズム
乗算には種々の方法がありますが,Pyxisでは2次のBoothアルゴリズムを利用しました.
このアルゴリズムを用いると,64ビットの固定小数点数を,ビット数の1/2の32クロックで,しかも2の補数表現のまま演算できることが大きな特長です.他の方法,例えば単純なシフト加算方式では処理に64クロックを必要とすることに加え,乗算器の入力を予め正数にしておく必要があります.またその際,符号は別に処理しなければなりません.加減算を含む各演算回路のデータ表現を統一することはシステム的に非常に有効です.そのためにも,乗算にBoothのアルゴリズムを使うことはこの場合最適といえます.
|
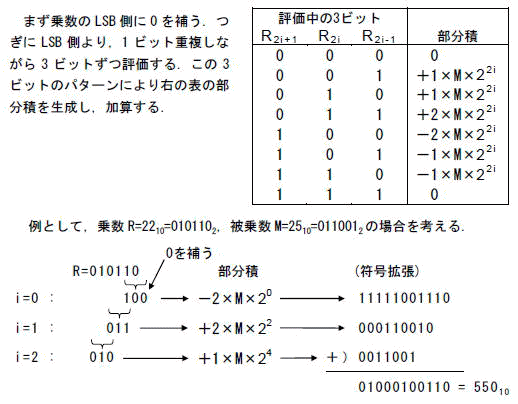
[図4-4]2次のBoothアルゴリズム
|
(2)構成と動作
(a)被乗数,乗数レジスタ
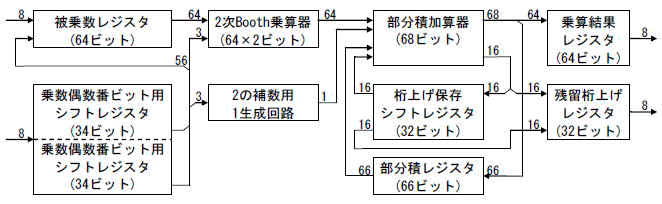
乗算回路の基本ブロック図を図4-5に示します.
被乗数レジスタは64ビットパラレル出力です.
乗数はシフトレジスタにロードされますが,これは2次Boothのため2ビットずつシフトする必要があります.そこで半分のサイズのシフトレジスタを2系列用意し,偶数番ビットと奇数番ビットを分けてそれぞれロード/シフトしています.そしてそのシフト出力(LSB側)の3ビットを乗数側データとして2次Booth乗算器に送っています.
|
[図4-5]乗算回路のブロック図
|
この両レジスタは,パイプラインのステージ間レジスタとしても機能しています.レジスタの入力側は加減算部(具体的には前項の加算・減算回路)と接続されており,そこからの出力は64ビットのLSB側より8ビットずつ8回に分けて送られてきます.乗数シフトレジスタは乗算処理の進行によりMSB側から空いてきます.この空きが8ビットになる瞬間に,加算・減算回路からの8ビット出力がそこへロードされるタイミング構成になっています.結果,例えばPEの乗算処理が終了した時点では,この乗数シフトレジスタにはPDのデータがすでに64ビット分ロードされていることになります.そして同時に,この最後の8ビットロードのタイミングで,乗数シフトレジスタにロード済みの56ビットとこの最後の8ビットを合わせて被乗数レジスタへロードし,被乗数を更新しています.
(b)2次Booth乗算器
2次Booth乗算器の実現には,LS261を用いています.これにより,図4-4にある被乗数64ビット×乗数2ビット(±2,±1,0)の部分積が得られます.
ただし,生成される部分積がM×(−2,−1)の場合のLS261からの出力は1の補数でしかないことに注意します.図4-5の中に
"2の補数用1生成回路" がありますが,ここで2の補数にするための1を生成しています.
(c)高速部分積加算
次にこの部分積を加算します.部分積レジスタはクロック0でクリアされ,以後クロック31まで部分積加算器の出力をクロック毎に一時的に保存します.以後,この部分積加算クロックをCKPAと表記します.
部分積加算器はLS283を17個使った68ビット加算回路ですが,このキャリーを1クロック中ですべて伝搬させると非常に時間を消費してしまいます.そこで,ここでも桁上げ保存を応用しています.これにより64ビット加算でありながら,キャリー伝搬のための無駄な時間を完全に排除しています.
図4-6に,乗算回路の動作を示します.この図を用いて,部分積加算における桁上げの高速処理を説明します.
|

[図4-6]乗算回路の動作−高速部分積加算
|
例として,部分積の中のLS2831個分(P56〜P59:図中*1)の,CKPA=1での動きで説明します.
4ビット全加算器LS283の入力には,それぞれ
・A4〜A1:部分積レジスタの出力Q54〜Q57
・B4〜B1:LS261から出力された部分積P56〜P59
・C0(桁上げ入力):C27の出力(現在初期化により0)
が入力され,その出力としてQ56〜Q59が得られています.この出力は次のCKPA=2の開始タイミングで,部分積レジスタのQ58〜Q61として2ビットずらしてロードされます.
これと同時に,LS283の桁上げ先見出力C4は,桁上げ保存シフトレジスタのC26にロードされます.そしてこのC26の内容は,次の次の加算クロックCKPA=3の開始タイミングでC27にシフトされ,その出力が桁上げとして加算されます.
LS283が4ビットの加算器であることと,乗数のシフトが2ビットずつであることから,保存された桁上げは本来の位取り位置に合わせるため2つ後の加算クロックにて処理しています.
少しややこしい処理ですが,桁上げを伝搬させないので高速な部分積加算が実現できます.このほかの動作は,図中の説明を参照してください.
(d)乗算結果レジスタ・残留桁上げレジスタ
乗算結果レジスタは64ビットパラレル入力のレジスタです.これにはCKPA=31の部分積加算器の出力が,次のCKPA=0の開始タイミングでロードされます.これが乗算結果ですが,一部の桁上げが桁上げ保存シフトレジスタに残っていますので,これも同時に残留桁上げレジスタ(32ビットパラレル入力)にロードします.そしてパイプラインの加減算部の先頭でこの両者を加算し,最終的な乗算結果を得ています.
この両レジスタは,乗数・被乗数レジスタ同様パイプラインのステージ間レジスタとしても機能しています.両レジスタの出力側がそれぞれ8ビットのバス接続になっており,64ビットを8ビットずつ8回に分けて,時分割で加減算部へ送っています.
乗算回路の速度は,Pyxisの性能を左右する重要な要素です.以上説明したように,2次Boothアルゴリズムを用いることで,2の補数64ビット同士の乗算を32回の部分積加算で実行します.また桁上げ保存の応用により,64ビットの部分積加算を行いながらも高速な動作が可能です.
実際の動作は,LSTTLベースの設計ながら,部分積加算クロックは12.5MHzです.基本的にはシフト加算方式ですが,64×64ビットを2.56μsecで演算しています.
このほか,パイプラインステージ間レジスタと,乗数・被乗数・乗算結果・残留桁上げの各レジスタを共用しています.さらにそれらへのロード/ストアを部分積加算クロックと同一タイミングで実行しています.データ転送のための無駄なクロックタイミングがないので,すべてのクロックに対して演算回路は100%の効率で動作します.
○次の項から,各機能ブロックの説明に入ります.その中で出てくる演算回路は,基本的に前述の加算・減算・乗算回路です.その組み合わせにより,大きな機能ブロックが構成されています.
4.4 Ox:Cx生成回路
ここは,式(1-4)の0からXMAX-1までの各xに対応するCxを,処理の進行に合わせて生成する部分です.
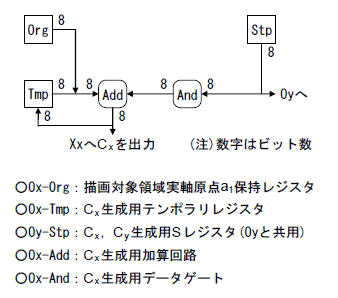
Oxのブロック図を図4-7に示します.
Org,Tmp,Stpはトライステート出力の64ビットレジスタで,出力は8ビット幅のバス構造になっています.これは4.2の加算回路構成であるOx-Add及びXxの加減算部への対応のため,8ビットずつ,8回に分けた時分割出力としています.
さて式(1-4)の乗算項は,もちろん乗算する必要はありません.x=0に対応するOrgを初期値として,これにStpを加算し,結果をXxの加減算部へ送ると同時にTmpへ保存します.このTmpとStpの加算と保存をxの1増加毎に行うことでCxを生成します.
これがCx生成法の基本ですが,パイプラインへの対応のためもう一工夫します.
Andは8個のAndゲートで構成されており,8ビットデータ(S)をそのまま通過させるか(×1),または出力を0とするか(×0)を制御するためのゲートです.
Xxの加減算部には,反復演算によりPEとPDのデータが交互に回ってきますので,Cxの値もそれに同期して交互に生成する必要があります.このため,まずTmpにはPEに対応するCxだけが保存されるようにします.そしてStpは常時出力しておき,Andの制御により0を加算するかSを加算するかを切り替えます.
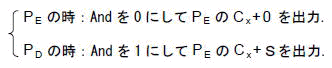
この間,Tmpは変更されません.
そしてピクセルペアの処理終了時に,TmpにSを2回加算します.反復終了時のPDに対応する出力Cx+SをTmpに保存し,さらに続いて開始される次のピクセルペアの処理の第1サイクルでAndを1にすると同時に出力をTmpにロードします.これで,次のピクセルペアに対するTmpが準備されます.
|
[図4-7]Oxのブロック図
|
4.5 Oy:Cy生成回路
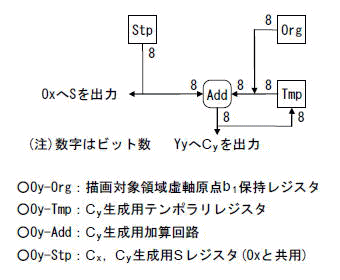
ここは,式(1-4)の0からYMAX-1までの各yに対応するCyを,処理の進行に合わせて生成する部分です.
ここの動作はOxと同様ですが,パイプラインに関する処理が不要なのでその機能はありません.単純にyの1増加毎にStpとTmpの加算と保存を行って,Cyを更新しています.
Oyのブロック図を図4-8に示します.
[図4-8]Oyのブロック図
|
4.6 Xx:Zx2−Zy2+Cx演算回路
ここには,Zxの2乗のための乗算回路と,Zx2−Zy2+Cxのための加減算回路があります.また,2乗の前の式(3-3)のチェックがあります.
ブロック図を図4-9に示します.
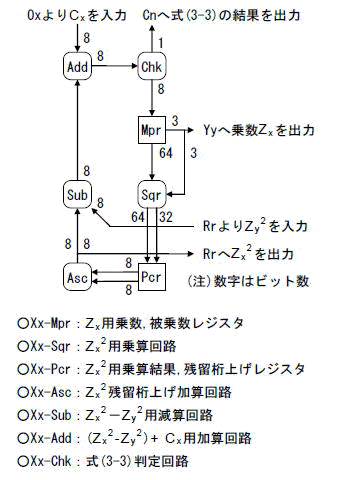
[図4-9]Xxのブロック図
|
4.7 Yy:2ZxZy+Cy演算回路
ここには,ZxZyのための乗算回路と,2Zx2Zy2+Cyのための加減算回路があります.またXx同様,2乗の前の式(3-4)のチェックがあります.
ブロック図を図4-10に示します.
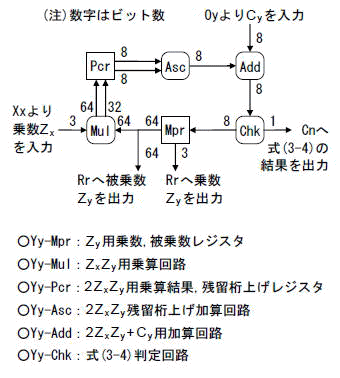
[図4-10]Yyのブロック図
|
4.8 Rr:Zx2+Zy2演算回路
ここには,Zyの2乗のための乗算回路と,Zx2+Zy2のための加減算回路があります.また,式(3-2)のチェックがあります.
ブロック図を図4-11に示します.
ここには乗数,被乗数レジスタはありません.
Xx,Yy内のレジスタ出力を同時に利用する事で,無駄な回路を省いています.
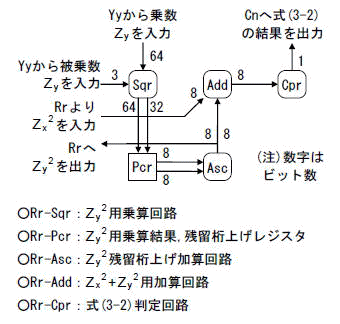
[図4-11]Rrのブロック図
|
4.9 Cn:制御回路
CnはPyxis各部の制御信号すべてを生成している部分で,次の3部分より構成されています.
・Cn-Cpu:ホストインターフェース
・Cn-Cnt:制御信号生成用同期カウンタ
・Cn-Gen:制御信号生成回路
(1)Cn-Cpu:ホストインターフェース
2.2での説明の通り,Pyxisは8ビットCPUバスに接続され,単純なI/Oとして動作します.表4-1に,内部レジスタの一覧を示します.これら内部レジスタへのインターフェース回路,アドレスデコーダなどが主な内容です.
なお,XMAX,YMAXは特に変更する必要性を感じなかったので内部で固定されており,それぞれ400,320です.
(2)Cn-Cnt:制御信号生成用同期カウンタ
ここは,制御信号を生成するために必要となる,内部状態をカウントする同期カウンタ部です.
機能上これは4つに分けられており,分周比の小さい方から,
(a)パイプライン1段の中の処理クロックである,
部分積加算クロックカウンタ(5ビット)と,
ピクセルペア区別用カウンタ(1ビット)
(b)式(1-1)の反復回数カウンタ(20ビット)
(c)xカウンタ(12ビット)
(d)yカウンタ(12ビット)
です.
しかし回路構成上では,この4つはシーケンシャルに接続された52ビットの完全同期カウンタになっており,12.5MHzの共通クロックで動作します.
通常の回路構成ではこのビット数を12.5MHzでカウントすることはできませんので,ちょっと凝った回路にしてみました.カウンタICに非同期キャリー出力のLS161を13個使用し,それ1個にANDゲートを2個ずつ付加して桁上げ先見しています.これにより飛躍的にクロックレートを上げることができます.
原理は簡単ですので説明は省略します.回路図を参照してください.
(3)Cn-Gen:制御信号生成回路
ここは,次の3つの部分で構成されています.
(a)Cn-Gen-Gn1〜4:制御信号生成回路
(b)Cn-Gen-Syn:パイプライン制御回路
(c)Cn-Gen-Cnr:演算結果レジスタ
(a)Cn-Gen-Gn1〜4:制御信号生成回路
前項のCn-Cntの出力を受けて,Pyxis各部の状態を制御する信号を生成,出力する部分です.設計当時の資料ですが,この制御信号と出力条件の一覧を付録1に示します.
(b)Cn-Gen-Syn:パイプライン制御回路
主に,2.3で説明した反復演算の終了処理に関する部分です.正直言って,ここの動作は複雑すぎて簡単に説明できません.この反復演算の終了シーケンスには10通りの場合があり(CPUの読み出しが遅い場合の一時停止の有無や,式(1-5)判定回路3つからの信号のパターン,PEが先に終了,PDが先に終了・・・の組み合わせ),そのそれぞれについての動作があります.設計時にも,動作,タイミングの検証にずいぶん時間がかかりました.
(c)Cn-Gen-Cnr:演算結果レジスタ
ピクセルペアPE,PDのそれぞれに対する演算結果がストアされるレジスタです.ホストの処理を軽減するため,反復がNMAX回行われたかどうかを示す1ビットのフラグMAXCNTが,結果のMSBにアサインされています.
|
<入力>
|
I/Oアドレス
|
|
リセットレジスタ(ビット0のみ有効:1でリセット)
|
080H
|
|
描画対象領域実軸原点a1レジスタ(8バイト)
|
0B0H〜0B7H
|
|
描画対象領域虚軸原点b1レジスタ(8バイト)
|
0A0H〜0A7H
|
|
Cx,Cy生成用ステップSレジスタ(8バイト)
|
0A8H〜0AFH
|
|
最大反復回数NMAXレジスタ(2バイト)
|
088H,090H
|
|
<出力>
|
I/Oアドレス
|
|
結果レジスタLE(2バイト)
|
09AH〜09BH
|
|
結果レジスタLD(2バイト)
|
09DH〜09EH
|
|
演算終了ステータスレジスタ(ビット0のみ有効:1で終了)
|
098H
|
|
[表4-1]内部レジスタ
|
4.10 回路図の構成
Pyxisの回路図はOrCADの階層構造を使ってかかれており,4階層全67枚で構成されています.1枚1枚がそれぞれ機能ブロックになっており,図面番号がその機能ブロックの内容を表現しています.
|
○図面番号の付け方
・図面番号はファイル名と共通で,最大8文字.
・第1階層は1枚のみで,図面番号は[Pyxis].
・第2階層以下は,機能ブロックの名称を次のように付ける.
図面番号=[22333444].
第2階層は2文字で,Ox,Oy,Xx,Yy,Rr,Cnのいづれか.
第3階層は3文字で,所属する第2階層名称の後に付加する.第4階層も同様.
|
ここまでの説明の中で出てきた各機能ブロックの名称はこのような形で図面番号と対応しており,それぞれ階層と機能がわかるようになっています.
付録5に回路図の階層情報を示します.
付録6にPyxisの全回路図を示します.
|